Most often in a conversation about big data, we hear a comparison between Apache Hadoop and Apache Spark. Both are big data frameworks; however, not really serve the same purpose.
Where Hadoop consists of whole components including data processing and distributed file system, Spark is a data processing tool that operates on distributed data collections.
Let’s take a look at what they do and how they differ.
Hadoop is a framework designed to work with huge amounts of data sets across computer clusters using the MapReduce programming model.
Spark is an open-source cluster computing framework generally used for large-scale data processing.
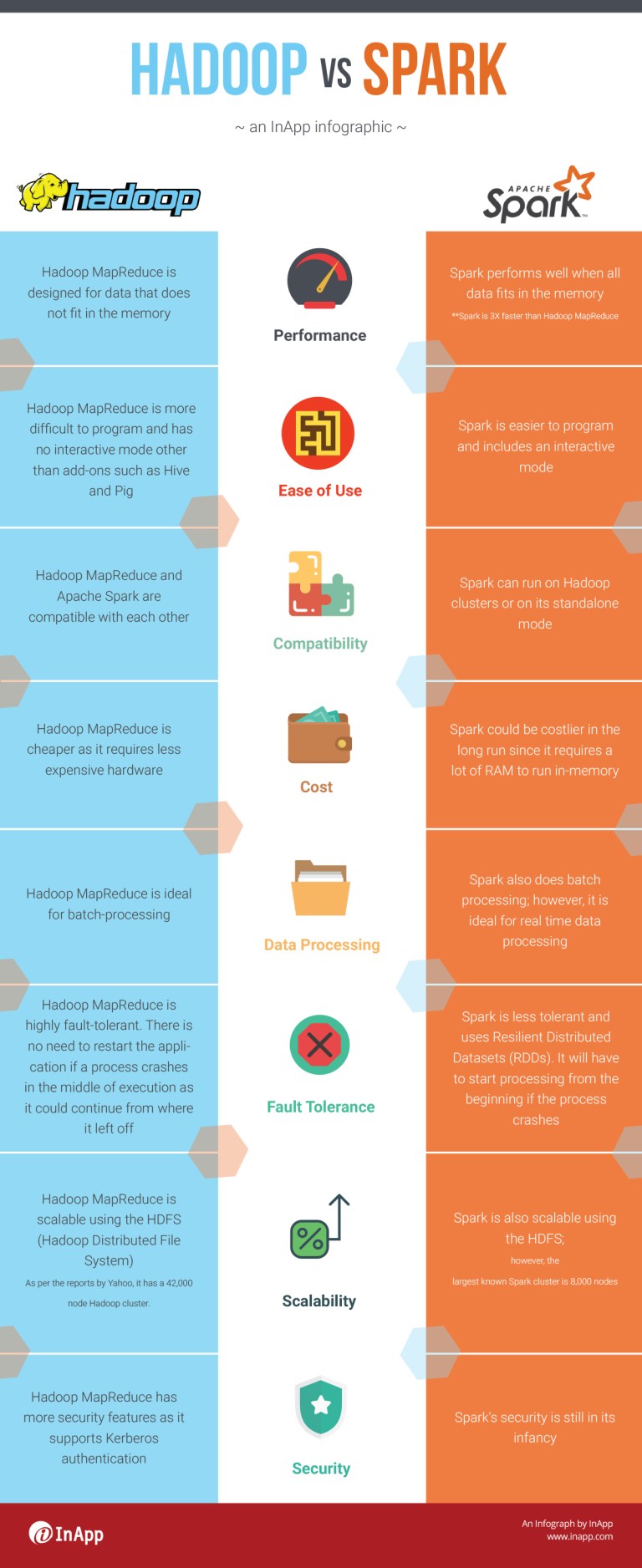
Difference between Hadoop and Spark
Performance
- Hadoop MapReduce is designed for data that does not fit in the memory.
- Spark performs well when all data fits in the memory (Spark is 3X faster than Hadoop MapReduce).
Ease of Use
- Hadoop is more difficult to program and has no interactive mode other than add-ons such as Hive and Pig
- Spark is easier to program and includes an interactive mode.
Compatibility
- Hadoop MapReduce and Spark are compatible with each other.
- Spark can run on Hadoop clusters or on its standalone mode.
Cost
- Hadoop is cheaper as it requires less expensive hardware.
- Spark could be costlier in the long run since it requires a lot of RAM t run in memory.
Data Processing
- Hadoop is ideal for batch processing.
- Spark also does batch processing: however, it is ideal for real-time data processing.
Fault Tolerance
- Hadoop is highly fault-tolerant. There is no need to restart the application if a process crashes in the middle of execution as it could continue from where it left off.
- Spark is less tolerant and uses Resilient Distributed Datasets (RDDs). It will have to start processing from the beginning of the process crashes.
Scalability
- Hadoop MapReduce is scalable using the HDFS (Hadoop Distributed File System) As per the reports by Yahoo, it has 42,000 node Hadoop clusters.
- Spark is also scalable using HDFS; however, the largest known Spark cluster is 8,000 nodes.
Security
- Hadoop has more security features as it supports Kerberos authentication.
- Spark’s security is still in its infancy.
Summary
Apache Spark and Apache Hadoop have a synergetic relationship with each other. The speed, agility, and relative ease of use of Spark complement the low cost of operation of Hadoop. Hadoop is the best choice for businesses that need huge datasets with batch processing, whereas Spark is ideal for applications that require fast and iterative processing.
